Engineered for Rigor #
Ready for Human Review
See all 9 supported workflows →
 Click to expand
Click to expand
 Docker Container
Docker Container
 Reproducible Python & R Environment
Reproducible Python & R Environment
Your AI-powered lab manager
With so much at stake, how do we actually fight the threat of AI slop? DAAF layers together a suite of architectural defenses and strategies from the current frontier of AI best practices to maximize AI output quality and force Claude Code to operate more like a careful and thoughtful researcher at every opportunity. Because LLM hallucinations can never be fully eliminated, the last line of defense and final call always rests with you as the PI.
Core Features #
Revise if failing
Research Coder Specialist
Draft script
Self-test & verify output
↺ Revise until passing
handoff
Code Reviewer Specialist
Adversarial review
Independent methodology & logic checks
Reviewer report
Causal Inference
In-depth references on DiD, RDD, IV, PSM, etc. methodologies with citations
Methodology reference
GitHub ↗
PyFixest
Function and library reference for high-performance fixed effects estimation and inference
Python library skill
GitHub ↗
Science Communication
Best practices for report writing, visualization design, and audience framing
General skill
GitHub ↗
College Scorecard
Dataset documentation reference on variable definitions, dataset collection context, and known data quality issues
Data source skill
GitHub ↗
Data Onboarding
Make Claude an expert in your data and data documentation
Data Lookup
Your personal data documentation oracle
Data Discovery
Connect the dots across data sources for rapid and thorough exploration
Full Pipeline
From research question to results, with your guidance every step of the way
Revision & Extension
Make the first draft better and build beyond
Reproducibility Verification
Conduct formal reproducibility verification analyses for any full pipeline project with DAAF
1Data Discovery
Human Review
2Analytic Planning
Human Review
3Data Acquisition
Human Review
4Data Analysis
Human Review
5Report Synthesis
Script versioning
04_create-bands.pyInitial draft
04_create-bands_a.pyApproved ✓
09_viz-boxplot-selectivity.pyInitial draft
09_viz-boxplot-selectivity_a.pyFix stat_summary bug
09_viz-boxplot-selectivity_b.pyApproved ✓
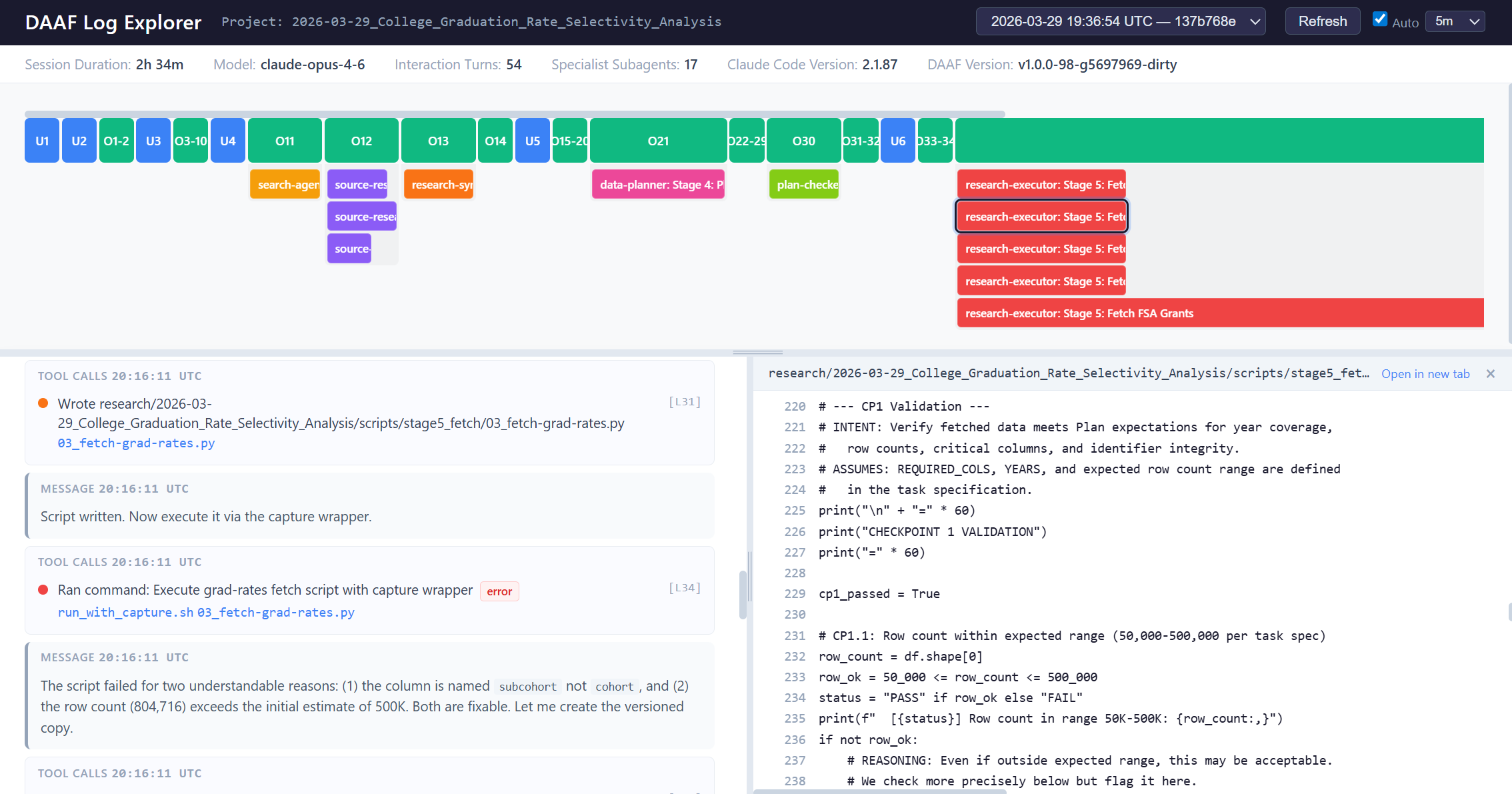
Session Log Explorer
Click to expand
👤 You
Your Computer
📂 Rest of Your Personal Files
🔒 Isolated
DAAF
 Claude Code
Claude Code
Instructions, workflows & references
Claude Code
📁
Docker-specific Filesystem
GUIDE-LLM
AI Disclosure Checklist for Publication
AUTO
Populated by DAAF
A.1Purpose of LLM use
A.2Human-in-the-loop oversight
B.1Model, provider & version
B.2Access method
B.3Parameters & configuration
B.4Fine-tuning or customization
B.5Session state retention
C.1Exact prompts reported
C.2System-wide instructions
E.1Human validation of outputs
F.1Code & scripts shared
YOU
Researcher completes
D.1Personal & sensitive data handling
E.2Post-processing of outputs
G.1Funding, support & relationships
--LLM choice rationale (optional)